

Recently my squad developed a microservice solution using an AWS Lambda and Node.js (Typescript) stack on top of Serverless, a framework which focuses on building and deploying serverless applications.
In this article, I will share my experience and learnings during this period.

A bit of context
Basically, the application goal was to consume an external API, do some processing on the retrieved data and post that result to a different API endpoint.
We considered that scenario as a great use case for Lambda, especially because the application would execute just twice per month; furthermore, we did not have to think about spinning up/configuring EC2 instances.
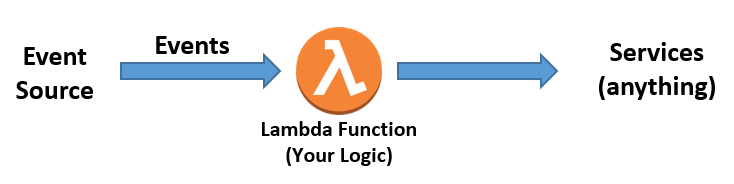
A basic workflow
Lambda
It is possible to write a Lambda function using several programming languages such as Javascript, Python, C#, Java and Go.
We decided on getting the safety benefits of the Typescript superset. That choice resulted in a learning curve since we hadn’t had previous work experience with Typescript. In addition, we used Aurelia for dependency injection management.
One of the main advantages of a Lambda function is that it does not demand a server configuration to be executed. In addition, the handlers will be automatically scaled according to how demanding the process is. If this is not desired, it is possible to define the maximum amount of concurrent Lambdas; any additional function will be throttled.
If your Lambda does a high memory-consuming task, you can increase this value, which will also improve the container’s CPU speed thus enhancing overall performance.
You can see a Lambda handler example, where a controller class is instantiated and its async method (publish) is called:
A Lambda handler example
Serverless Framework
By using the Serverless framework, we could structure our code in services where the AWS Lambda functions and their triggering events were defined.
The framework is not opinionated in a way that enforces the developers to follow a specific structure, so you are free to decide how to organise your code according to your needs. Regarding our requirements, we decided to use controllers, models and services because we considered them a good balance between organisation and simplicity.
The Serverless framework abstracts all the Lambda configuration in a way that you do not have to reach the AWS Console to setup any required piece of AWS infrastructure.
It is possible to set environment variables, memory size, timeout, link to a VPC or even configure a CRON event (to schedule the execution of the Lambda function) through a YAML configuration file.
The CLI provides a command to deploy the application from your local environment to AWS. Once you have supplied credentials through the sls login command, you will be able to use sls deploy to publish your service to your cloud provider.
A Serverless Framework configuration file example
Local development
We have been using the lambci/lambda Docker image to test the application in our local workstations, which resembles the AWS Lambda environment. As an alternative, the LocalStack can be used as a solution to achieve the same purpose.
Locally testing a Lambda function with lambci Docker image
Queues
We used the AWS SQS (Simple Queue Service) to achieve our goal.
After retrieving the initial data from an API, we push each individual row as a SQS message. Because of the SQS/Lambda integration, a Lambda function can be automatically invoked when a message gets in the queue. That’s when our consumer kicks in and do the processing.
Another important aspect is that when an error occurs, the message is sent to the dead-letter queue (after the amount of retries configured in the redrive policy).
Once in a dead-letter queue, we can analyse what went wrong in that particular occurrence and adopt a strategy to replay the message, if that is the case. As of now, there is no automatic way (such as RabbitMQ’s “move messages” function) to send a message from dead-letter queue back to the original one through AWS Console. Therefore, you would have to do it via code or manually.
Unit testing
We have used Jest, which supports Typescript through ts-jest package, for unit testing. It implements a sandboxed execution for all tests and built-in coverage reports. This was particularly useful since we aimed to keep our code to 100% coverage.
Jest’s test cases structure is quite similar to other testing frameworks such as PHPUnit, which we were more used to.
It does not rely on Amazon runtime environment and you can use the aws-sdk-mock package to help testing any AWS calls.
A Jest test to check if a Fetch Factory was successfully instantiated
Continuous Integration/Continuous Deployment
In keeping with our architecture standards, the CI/CD was executed around Bamboo and relied on Terraform scripts. This fact allowed more flexibility to our application, since we could use broader configuration options and avoided being “locked in” to Serverless framework.
To illustrate this, Terraform scripts were used to set: CloudWatch metric alarms, SNS topics (notification), IAM permissions (Identity and Access Management), SQS queues and security groups for VPCs (allowing to make a request to an external API).
When a feature branch is pushed to GitHub, it triggers a Bamboo’s build execution plan with parallel tasks such as: code styling checks and unit tests. If this entire process is successful, we can deploy that branch into an AWS “dev” or “staging” environment. Only after Quality Assurance and User Acceptance Test phases that the branch can be merged with master and released into production.
A SQS configuration via Terraform
Monitoring
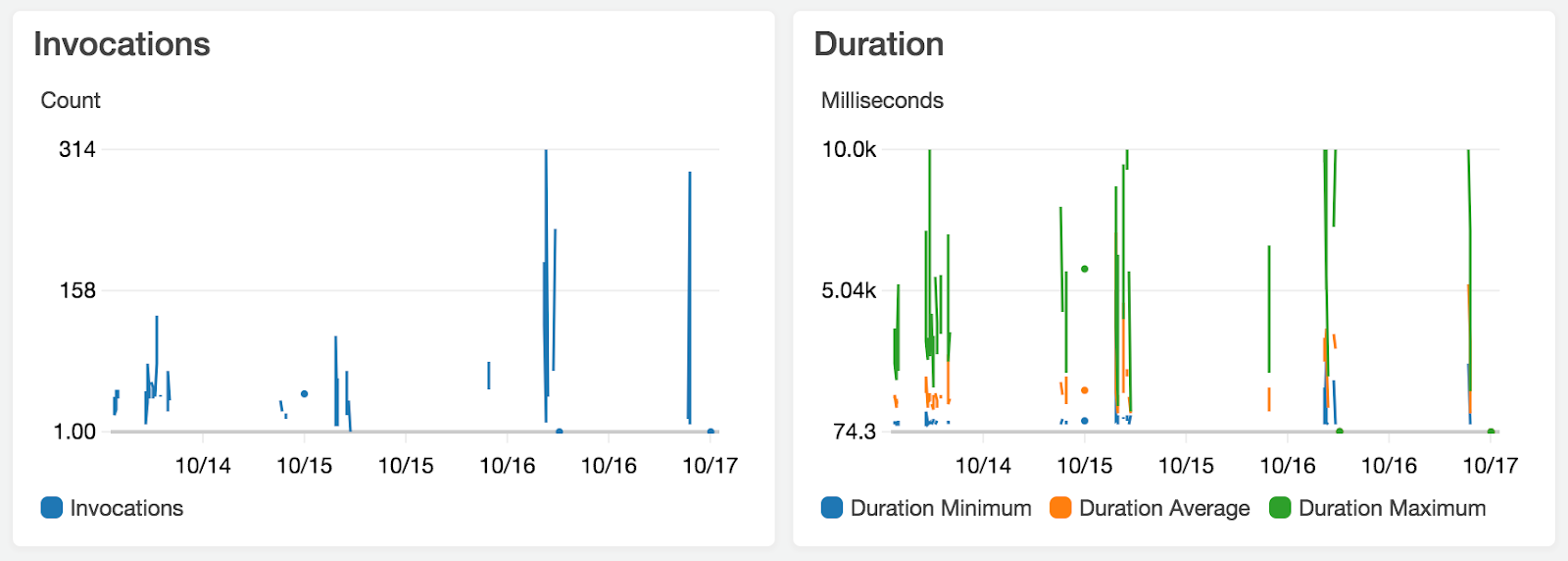
The AWS Console provides several graphic metrics to monitor our application. It is possible to check the amount of Lambda invocations, errors and concurrent executions, as well as the process duration in a desired period.
Besides that, one can see all the application logs in the CloudWatch service. An integration between CloudWatch and OpsGenie was setup and we are able to receive error notifications via SMS/Push/email as soon as they happen. All logs are sent to LogEntries, and we can monitor them using the same platform used for “regular” applications.
For those who are keen to an external integration, at the time of this article’s creation, New Relic APM (Application Performance Monitoring) for Lambda is in beta stage.
Considerations
The fault tolerance, automatic scalability/concurrency, easiness to create different staging environments and seamless integration with a large array of cloud services are some of the main advantages.
In addition, Lambda is cheaper when compared to a traditional server instance, unless you have heavy workloads with a large number of long-lasting functions. Cloud providers as AWS and Google offer a competitive pricing (1 million for the first and 2 million free requests/month for the latter and something around $0.2 per 1 million requests thereafter).
On the other hand, when you are developing a customer facing application, the “cold start” period is something that you should consider. If latency is really critical, an EC2 instance would be more suitable since it will be up and accepting connections as long and as quickly as it is configured to do so.
In terms of security, Lambda functions are, by design, more DDoS attack resistants than EC2 instances, even if you are exposing them to external access (via API Gateway, for instance). This is due to rate-based blacklisting, timeouts and the fact that containers are spun up and down on demand. To achieve the same protection against heavy loads on EC2 instances you would have to configure a firewall, elastic IP services and load balancers.
Of course you need to take into account all your business requirements, but if you are considering creating a microservice application, especially with short tasks, going serverless seems to be a very reasonable choice.
This post was originally published on THE ICONIC Tech blog.